The Databricks Certified Generative AI Engineer Associate (Databricks-Generative-AI-Engineer-Associate)
Passing Databricks Generative AI Engineer exam ensures for the successful candidate a powerful array of professional and personal benefits. The first and the foremost benefit comes with a global recognition that validates your knowledge and skills, making possible your entry into any organization of your choice.


Databricks-Generative-AI-Engineer-Associate Exam Dumps
- Exam Code: Databricks-Generative-AI-Engineer-Associate
- Vendor: Databricks
- Certifications: Generative AI Engineer
- Exam Name: Databricks Certified Generative AI Engineer Associate
Why CertAchieve is Better than Standard Databricks-Generative-AI-Engineer-Associate Dumps
In 2026, Databricks uses variable topologies. Basic dumps will fail you.
| Quality Standard | Generic Dump Sites | CertAchieve Premium Prep |
|---|---|---|
| Technical Explanation | None (Answer Key Only) | Step-by-Step Expert Rationales |
| Syllabus Coverage | Often Outdated (v1.0) | 2026 Updated (Latest Syllabus) |
| Scenario Mastery | Blind Memorization | Conceptual Logic & Troubleshooting |
| Instructor Access | No Post-Sale Support | 24/7 Professional Help |
Customers Passed Exams
10
Success backed by proven exam prep tools
Questions Came Word for Word
94%
Real exam match rate reported by verified users
Average Score in Real Testing Centre
90%
Consistently high performance across certifications
Study Time Saved With CertAchieve
60%
Efficient prep that reduces study hours significantly
Databricks Databricks-Generative-AI-Engineer-Associate Exam Domains Q&A
Certified instructors verify every question for 100% accuracy, providing detailed, step-by-step explanations for each.
Question 1
Databricks Databricks-Generative-AI-Engineer-Associate
QUESTION DESCRIPTION:
A Generative Al Engineer is developing a RAG system for their company to perform internal document Q & A for structured HR policies, but the answers returned are frequently incomplete and unstructured It seems that the retriever is not returning all relevant context The Generative Al Engineer has experimented with different embedding and response generating LLMs but that did not improve results.
Which TWO options could be used to improve the response quality?
Choose 2 answers
Correct Answer & Rationale:
Answer: A, B
Explanation:
The problem describes a Retrieval-Augmented Generation (RAG) system for HR policy Q & A where responses are incomplete and unstructured due to the retriever failing to return sufficient context. The engineer has already tried different embedding and response-generating LLMs without success, suggesting the issue lies in the retrieval process—specifically, how documents are chunked and indexed. Let’s evaluate the options.
Option A: Add the section header as a prefix to chunks
Adding section headers provides additional context to each chunk, helping the retriever understand the chunk’s relevance within the document structure (e.g., “Leave Policy: Annual Leave” vs. just “Annual Leave”). This can improve retrieval precision for structured HR policies.
Databricks Reference : "Metadata, such as section headers, can be appended to chunks to enhance retrieval accuracy in RAG systems" ("Databricks Generative AI Cookbook," 2023).
Option B: Increase the document chunk size
Larger chunks include more context per retrieval, reducing the chance of missing relevant information split across smaller chunks. For structured HR policies, this can ensure entire sections or rules are retrieved together.
Databricks Reference : "Increasing chunk size can improve context completeness, though it may trade off with retrieval specificity" ("Building LLM Applications with Databricks").
Option C: Split the document by sentence
Splitting by sentence creates very small chunks, which could exacerbate the problem by fragmenting context further. This is likely why the current system fails—it retrieves incomplete snippets rather than cohesive policy sections.
Databricks Reference : No specific extract opposes this, but the emphasis on context completeness in RAG suggests smaller chunks worsen incomplete responses.
Option D: Use a larger embedding model
A larger embedding model might improve vector quality, but the question states that experimenting with different embedding models didn’t help. This suggests the issue isn’t embedding quality but rather chunking/retrieval strategy.
Databricks Reference : Embedding models are critical, but not the focus when retrieval context is the bottleneck.
Option E: Fine tune the response generation model
Fine-tuning the LLM could improve response coherence, but if the retriever doesn’t provide complete context, the LLM can’t generate full answers. The root issue is retrieval, not generation.
Databricks Reference : Fine-tuning is recommended for domain-specific generation, not retrieval fixes ("Generative AI Engineer Guide").
Conclusion : Options A and B address the retrieval issue directly by enhancing chunk context—either through metadata (A) or size (B)—aligning with Databricks’ RAG optimization strategies. C would worsen the problem, while D and E don’t target the root cause given prior experimentation.
Question 2
Databricks Databricks-Generative-AI-Engineer-Associate
QUESTION DESCRIPTION:
A Generative Al Engineer is creating an LLM-based application. The documents for its retriever have been chunked to a maximum of 512 tokens each. The Generative Al Engineer knows that cost and latency are more important than quality for this application. They have several context length levels to choose from.
Which will fulfill their need?
Correct Answer & Rationale:
Answer: D
Explanation:
When prioritizing cost and latency over quality in a Large Language Model (LLM)-based application, it is crucial to select a configuration that minimizes both computational resources and latency while still providing reasonable performance. Here's why D is the best choice:
Context length : The context length of 512 tokens aligns with the chunk size used for the documents (maximum of 512 tokens per chunk). This is sufficient for capturing the needed information and generating responses without unnecessary overhead.
Smallest model size : The model with a size of 0.13GB is significantly smaller than the other options. This small footprint ensures faster inference times and lower memory usage, which directly reduces both latency and cost.
Embedding dimension : While the embedding dimension of 384 is smaller than the other options, it is still adequate for tasks where cost and speed are more important than precision and depth of understanding.
This setup achieves the desired balance between cost-efficiency and reasonable performance in a latency-sensitive, cost-conscious application.
Question 3
Databricks Databricks-Generative-AI-Engineer-Associate
QUESTION DESCRIPTION:
A Generative Al Engineer has developed an LLM application to answer questions about internal company policies. The Generative AI Engineer must ensure that the application doesn’t hallucinate or leak confidential data.
Which approach should NOT be used to mitigate hallucination or confidential data leakage?
Correct Answer & Rationale:
Answer: B
Explanation:
When addressing concerns of hallucination and data leakage in an LLM application for internal company policies, fine-tuning the model on internal data with the hope it learns data boundaries can be problematic:
Risk of Data Leakage : Fine-tuning on sensitive or confidential data does not guarantee that the model will not inadvertently include or reference this data in its outputs. There’s a risk of overfitting to the specific data details, which might lead to unintended leakage.
Hallucination : Fine-tuning does not necessarily mitigate the model's tendency to hallucinate; in fact, it might exacerbate it if the training data is not comprehensive or representative of all potential queries.
Better Approaches:
A , C , and D involve setting up operational safeguards and constraints that directly address data leakage and ensure responses are aligned with specific user needs and security levels.
Fine-tuning lacks the targeted control needed for such sensitive applications and can introduce new risks, making it an unsuitable approach in this context.
Question 4
Databricks Databricks-Generative-AI-Engineer-Associate
QUESTION DESCRIPTION:
A Generative AI Engineer is building a RAG application that will rely on context retrieved from source documents that are currently in PDF format. These PDFs can contain both text and images. They want to develop a solution using the least amount of lines of code.
Which Python package should be used to extract the text from the source documents?
Correct Answer & Rationale:
Answer: B
Explanation:
Problem Context : The engineer needs to extract text from PDF documents, which may contain both text and images. The goal is to find a Python package that simplifies this task using the least amount of code.
Explanation of Options :
Option A: flask : Flask is a web framework for Python, not suitable for processing or extracting content from PDFs.
Option B: beautifulsoup : Beautiful Soup is designed for parsing HTML and XML documents, not PDFs.
Option C: unstructured : This Python package is specifically designed to work with unstructured data, including extracting text from PDFs. It provides functionalities to handle various types of content in documents with minimal coding, making it ideal for the task.
Option D: numpy : Numpy is a powerful library for numerical computing in Python and does not provide any tools for text extraction from PDFs.
Given the requirement, Option C (unstructured) is the most appropriate as it directly addresses the need to efficiently extract text from PDF do cuments with minimal code.
Question 5
Databricks Databricks-Generative-AI-Engineer-Associate
QUESTION DESCRIPTION:
A Generative AI Engineer is using LangGraph to define multiple tools in a single agentic application. They want to enable the main orchestrator LLM to decide on its own which tools are most appropriate to call for a given prompt. To do this, they must determine the general flow of the code. Which sequence will do this?
Correct Answer & Rationale:
Answer: B
Explanation:
In modern agentic frameworks like LangGraph or LangChain, the standard workflow for creating an autonomous tool-calling agent follows a specific sequence. First, tools must be defined (often as Python functions with clear docstrings, which the LLM uses to understand the tool's purpose). Second, the agent logic is defined, which specifies how the LLM should think. Third, the agent is initialized using a logic pattern like ReAct (Reason + Act). The ReAct framework is essential here because it enables the "orchestrator" loop: the LLM receives a prompt, generates a "Thought" about which tool to use, generates an "Action" to call that tool, receives an "Observation" (the tool's output), and repeats until it can provide a final answer. Loading tools into "separate agents" (C) or defining tools "inside" agents (D) are non-standard patterns that add unnecessary complexity and do not align with the centralized orchestration model required for LangGraph.
Question 6
Databricks Databricks-Generative-AI-Engineer-Associate
QUESTION DESCRIPTION:
A Generative AI Engineer is developing an agent system using a popular agent-authoring library. The agent comprises multiple parallel and sequential chains. The engineer encounters challenges as the agent fails at one of the steps, making it difficult to debug the root cause. They need to find an appropriate approach to research this issue and discover the cause of failure. Which approach do they choose?
Correct Answer & Rationale:
Answer: A
Explanation:
For complex agentic systems (like those built with LangGraph or Autogen), standard logging is often insufficient because the "state" of the agent changes dynamically. MLflow Tracing is the designated Generative AI engineering standard for debugging these systems. Tracing provides a visual, hierarchical timeline of every call made during an agent's execution—including internal LLM reasoning, tool calls, and data transformations. When a step fails, the trace allows the engineer to click into that specific node to see the exact input sent to the LLM and the raw output received. This is much faster and more comprehensive than manually deconstructing the agent (D) or adding manual logs (C). While mlflow.evaluate (B) is useful for measuring performance across a whole dataset, it is not a tool for real-time debugging of a single execution failure.
Question 7
Databricks Databricks-Generative-AI-Engineer-Associate
QUESTION DESCRIPTION:
What is an effective method to preprocess prompts using custom code before sending them to an LLM?
Correct Answer & Rationale:
Answer: D
Explanation:
The most effective way to preprocess prompts using custom code is to write a custom model, such as an MLflow PyFunc model . Here’s a breakdown of why this is the correct approach:
MLflow PyFunc Models : MLflow is a widely used platform for managing the machine learning lifecycle, including experimentation, reproducibility, and deployment. A PyFunc model is a generic Python function model that can implement custom logic, which includes preprocessing prompts.
Preprocessing Prompts : Preprocessing could include various tasks like cleaning up the user input, formatting it according to specific rules, or augmenting it with additional context before passing it to the LLM. Writing this preprocessing as part of a PyFunc model allows the custom code to be managed, tested, and deployed easily.
Modular and Reusable : By separating the preprocessing logic into a PyFunc model, the system becomes modular, making it easier to maintain and update without needing to modify the core LLM or retrain it.
Why Other Options Are Less Suitable :
A (Modify LLM’s Internal Architecture) : Directly modifying the LLM's architecture is highly impractical and can disrupt the model’s performance. LLMs are typically treated as black-box models for tasks like prompt processing.
B (Avoid Custom Code) : While it’s true that LLMs haven't been explicitly trained with preprocessed prompts, preprocessing can still improve clarity and alignment with desired input formats without confusing the model.
C (Postprocessing Outputs) : While postprocessing the output can be useful, it doesn't address the need for clean and well-formatted inputs, which directly affect the quality of the model's responses.
Thus, using an MLflow PyFunc model allows for flexible and controlled preprocessing of prompts in a scalable way, making it the most effective method.
Question 8
Databricks Databricks-Generative-AI-Engineer-Associate
QUESTION DESCRIPTION:
A Generative AI Engineer is developing a chatbot designed to assist users with insurance-related queries. The chatbot is built on a large language model (LLM) and is conversational. However, to maintain the chatbot’s focus and to comply with company policy, it must not provide responses to questions about politics. Instead, when presented with political inquiries, the chatbot should respond with a standard message:
“Sorry, I cannot answer that. I am a chatbot that can only answer questions around insurance.”
Which framework type should be implemented to solve this?
Correct Answer & Rationale:
Answer: A
Explanation:
In this scenario, the chatbot must avoid answering political questions and instead provide a standard message for such inquiries. Implementing a Safety Guardrail is the appropriate solution for this:
What is a Safety Guardrail? Safety guardrails are mechanisms implemented in Generative AI systems to ensure the model behaves within specific bounds. In this case, it ensures the chatbot does not answer politically sensitive or irrelevant questions, which aligns with the business rules.
Preventing Responses to Political Questions : The Safety Guardrail is programmed to detect specific types of inquiries (like political questions) and prevent the model from generating responses outside its intended domain. When such queries are detected, the guardrail intervenes and provides a pre-defined response: “Sorry, I cannot answer that. I am a chatbot that can only answer questions around insurance.”
How It Works in Practice : The LLM system can include a classification layer or trigger rules based on specific keywords related to politics. When such terms are detected, the Safety Guardrail blocks the normal generation flow and responds with the fixed message.
Why Other Options Are Less Suitable :
B (Security Guardrail) : This is more focused on protecting the system from security vulnerabilities or data breaches, not controlling the conversational focus.
C (Contextual Guardrail) : While context guardrails can limit responses based on context, safety guardrails are specifically about ensuring the chatbot stays within a safe conversational scope.
D (Compliance Guardrail) : Compliance guardrails are often related to legal and regulatory adherence, which is not directly relevant here.
Therefore, a Safety Guardrail is the right framework to ensure the chatbot only answers insurance-related queries and avoids political discussions.
Question 9
Databricks Databricks-Generative-AI-Engineer-Associate
QUESTION DESCRIPTION:
A Generative AI Engineer just deployed an LLM application at a digital marketing company that assists with answering customer service inquiries.
Which metric should they monitor for their customer service LLM application in production?
Correct Answer & Rationale:
Answer: A
Explanation:
When deploying an LLM application for customer service inquiries, the primary focus is on measuring the operational efficiency and quality of the responses. Here's why A is the correct metric:
Number of customer inquiries processed per unit of time : This metric tracks the throughput of the customer service system, reflecting how many customer inquiries the LLM application can handle in a given time period (e.g., per minute or hour). High throughput is crucial in customer service applications where quick response times are essential to user satisfaction and business efficiency.
Real-time performance monitoring : Monitoring the number of queries processed is an important part of ensuring that the model is performing well under load, especially during peak traffic times. It also helps ensure the system scales properly to meet demand.
Why other options are not ideal:
B. Energy usage per query : While energy efficiency is a consideration, it is not the primary concern for a customer-facing application where user experience (i.e., fast and accurate responses) is critical.
C. Final perplexity scores for the training of the model : Perplexity is a metric for model training, but it doesn't reflect the real-time operational performance of an LLM in production.
D. HuggingFace Leaderboard values for the base LLM : The HuggingFace Leaderboard is more relevant during model selection and benchmarking. However, it is not a direct measure of the model's performance in a specific customer service application in production.
Focusing on throughput (inquiries processed per unit time) ensures that the LLM application is meeting business needs for fast and efficient customer service responses.
Question 10
Databricks Databricks-Generative-AI-Engineer-Associate
QUESTION DESCRIPTION:
A Generative Al Engineer is ready to deploy an LLM application written using Foundation Model APIs. They want to follow security best practices for production scenarios
Which authentication method should they choose?
Correct Answer & Rationale:
Answer: A
Explanation:
The task is to deploy an LLM application using Foundation Model APIs in a production environment while adhering to security best practices. Authentication is critical for securing access to Databricks resources, such as the Foundation Model API. Let’s evaluate the options based on Databricks’ security guidelines for production scenarios.
Option A: Use an access token belonging to service principals
Service principals are non-human identities designed for automated workflows and applications in Databricks. Using an access token tied to a service principal ensures that the authentication is scoped to the application, follows least-privilege principles (via role-based access control), and avoids reliance on individual user credentials. This is a security best practice for production deployments.
Databricks Reference : "For production applications, use service principals with access tokens to authenticate securely, avoiding user-specific credentials" ("Databricks Security Best Practices," 2023). Additionally, the "Foundation Model API Documentation" states: "Service principal tokens are recommended for programmatic access to Foundation Model APIs."
Option B: Use a frequently rotated access token belonging to either a workspace user or a service principal
Frequent rotation enhances security by limiting token exposure, but tying the token to a workspace user introduces risks (e.g., user account changes, broader permissions). Including both user and service principal options dilutes the focus on application-specific security, making this less ideal than a service-principal-only approach. It also adds operational overhead without clear benefits over Option A.
Databricks Reference : "While token rotation is a good practice, service principals are preferred over user accounts for application authentication" ("Managing Tokens in Databricks," 2023).
Option C: Use OAuth machine-to-machine authentication
OAuth M2M (e.g., client credentials flow) is a secure method for application-to-service communication, often using service principals under the hood. However, Databricks’ Foundation Model API primarily supports personal access tokens (PATs) or service principal tokens over full OAuth flows for simplicity in production setups. OAuth M2M adds complexity (e.g., managing refresh tokens) without a clear advantage in this context.
Databricks Reference : "OAuth is supported in Databricks, but service principal tokens are simpler and sufficient for most API-based workloads" ("Databricks Authentication Guide," 2023).
Option D: Use an access token belonging to any workspace user
Using a user’s access token ties the application to an individual’s identity, violating security best practices. It risks exposure if the user leaves, changes roles, or has overly broad permissions, and it’s not scalable or auditable for production.
Databricks Reference : "Avoid using personal user tokens for production applications due to security and governance concerns" ("Databricks Security Best Practices," 2023).
Conclusion : Option A is the best choice, as it uses a service principal’s access token, aligning with Databricks’ security best practices for production LLM applications. It ensures secure, application-specific authentication with minimal complexity, as explicitly recommended for Foundation Model API deployments.

Verified by Certified Instructors
This Databricks Databricks-Generative-AI-Engineer-Associate study pack was audited and verified on June 25, 2026 by Hilary Beaumont,. We ensure every technical rationale aligns with real-world enterprise standards.
A Stepping Stone for Enhanced Career Opportunities
Your profile having Generative AI Engineer certification significantly enhances your credibility and marketability in all corners of the world. The best part is that your formal recognition pays you in terms of tangible career advancement. It helps you perform your desired job roles accompanied by a substantial increase in your regular income. Beyond the resume, your expertise imparts you confidence to act as a dependable professional to solve real-world business challenges.
Your success in Databricks Databricks-Generative-AI-Engineer-Associate certification exam makes your visible and relevant in the fast-evolving tech landscape. It proves a lifelong investment in your career that give you not only a competitive advantage over your non-certified peers but also makes you eligible for a further relevant exams in your domain.
What You Need to Ace Databricks Exam Databricks-Generative-AI-Engineer-Associate
Achieving success in the Databricks-Generative-AI-Engineer-Associate Databricks exam requires a blending of clear understanding of all the exam topics, practical skills, and practice of the actual format. There's no room for cramming information, memorizing facts or dependence on a few significant exam topics. It means your readiness for exam needs you develop a comprehensive grasp on the syllabus that includes theoretical as well as practical command.
Here is a comprehensive strategy layout to secure peak performance in Databricks-Generative-AI-Engineer-Associate certification exam:
- Develop a rock-solid theoretical clarity of the exam topics
- Begin with easier and more familiar topics of the exam syllabus
- Make sure your command on the fundamental concepts
- Focus your attention to understand why that matters
- Ensure hands-on practice as the exam tests your ability to apply knowledge
- Develop a study routine managing time because it can be a major time-sink if you are slow
- Find out a comprehensive and streamlined study resource for your help
Ensuring Outstanding Results in Exam Databricks-Generative-AI-Engineer-Associate!
In the backdrop of the above prep strategy for Databricks-Generative-AI-Engineer-Associate Databricks exam, your primary need is to find out a comprehensive study resource. It could otherwise be a daunting task to achieve exam success. The most important factor that must be kep in mind is make sure your reliance on a one particular resource instead of depending on multiple sources. It should be an all-inclusive resource that ensures conceptual explanations, hands-on practical exercises, and realistic assessment tools.
Certachieve: A Reliable All-inclusive Study Resource
Certachieve offers multiple study tools to do thorough and rewarding Databricks-Generative-AI-Engineer-Associate exam prep. Here's an overview of Certachieve's toolkit:
Databricks Databricks-Generative-AI-Engineer-Associate PDF Study Guide
This premium guide contains a number of Databricks Databricks-Generative-AI-Engineer-Associate exam questions and answers that give you a full coverage of the exam syllabus in easy language. The information provided efficiently guides the candidate's focus to the most critical topics. The supportive explanations and examples build both the knowledge and the practical confidence of the exam candidates required to confidently pass the exam. The demo of Databricks Databricks-Generative-AI-Engineer-Associate study guide pdf free download is also available to examine the contents and quality of the study material.
Databricks Databricks-Generative-AI-Engineer-Associate Practice Exams
Practicing the exam Databricks-Generative-AI-Engineer-Associate questions is one of the essential requirements of your exam preparation. To help you with this important task, Certachieve introduces Databricks Databricks-Generative-AI-Engineer-Associate Testing Engine to simulate multiple real exam-like tests. They are of enormous value for developing your grasp and understanding your strengths and weaknesses in exam preparation and make up deficiencies in time.
These comprehensive materials are engineered to streamline your preparation process, providing a direct and efficient path to mastering the exam's requirements.
Databricks Databricks-Generative-AI-Engineer-Associate exam dumps
These realistic dumps include the most significant questions that may be the part of your upcoming exam. Learning Databricks-Generative-AI-Engineer-Associate exam dumps can increase not only your chances of success but can also award you an outstanding score.
Top Exams & Certification Providers
New & Trending
- New Released Exams
- Related Exam
- Hot Vendor
Verified Performance Reports
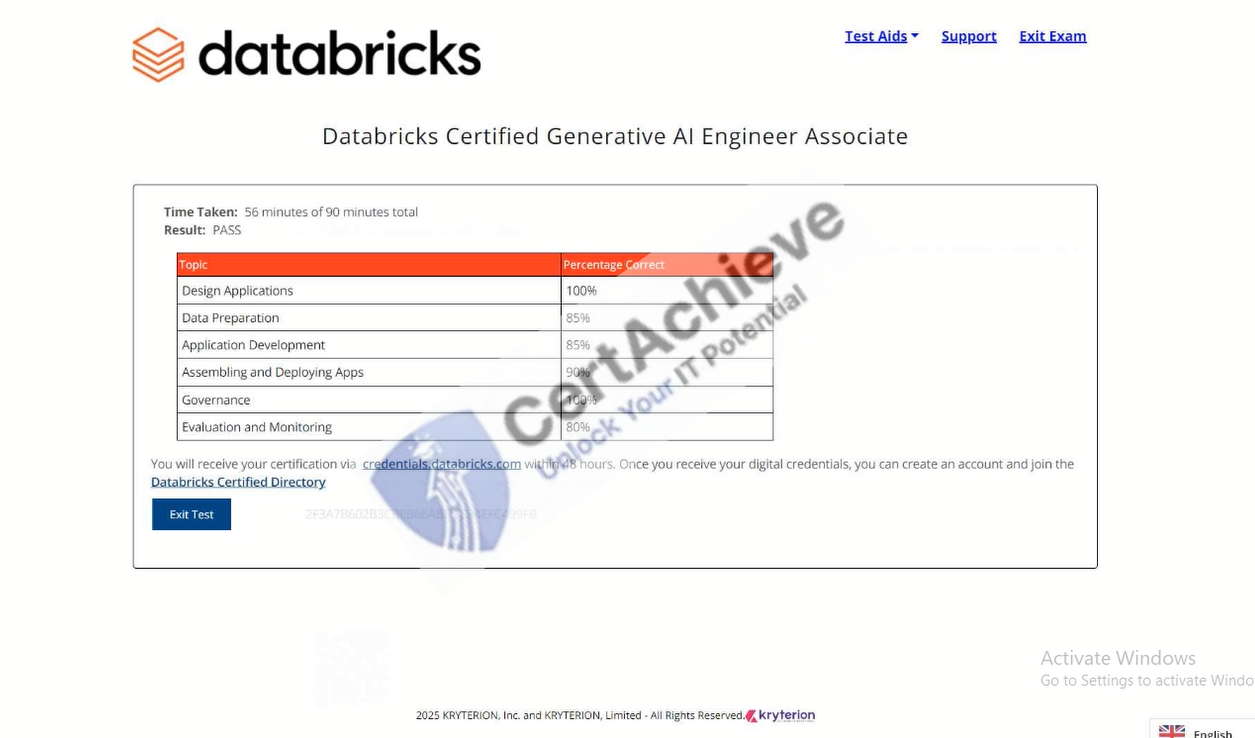
Authentic score reports from candidates who cleared the Databricks-Generative-AI-Engineer-Associate exam.
Verified Case #1
×
![]()