The Databricks Certified Data Engineer Associate Exam (Databricks-Certified-Data-Engineer-Associate)
Passing Databricks Databricks Certification exam ensures for the successful candidate a powerful array of professional and personal benefits. The first and the foremost benefit comes with a global recognition that validates your knowledge and skills, making possible your entry into any organization of your choice.


Databricks-Certified-Data-Engineer-Associate Exam Dumps
- Exam Code: Databricks-Certified-Data-Engineer-Associate
- Vendor: Databricks
- Certifications: Databricks Certification
- Exam Name: Databricks Certified Data Engineer Associate Exam
Why CertAchieve is Better than Standard Databricks-Certified-Data-Engineer-Associate Dumps
In 2026, Databricks uses variable topologies. Basic dumps will fail you.
| Quality Standard | Generic Dump Sites | CertAchieve Premium Prep |
|---|---|---|
| Technical Explanation | None (Answer Key Only) | Step-by-Step Expert Rationales |
| Syllabus Coverage | Often Outdated (v1.0) | 2026 Updated (Latest Syllabus) |
| Scenario Mastery | Blind Memorization | Conceptual Logic & Troubleshooting |
| Instructor Access | No Post-Sale Support | 24/7 Professional Help |
Customers Passed Exams
10
Success backed by proven exam prep tools
Questions Came Word for Word
86%
Real exam match rate reported by verified users
Average Score in Real Testing Centre
89%
Consistently high performance across certifications
Study Time Saved With CertAchieve
60%
Efficient prep that reduces study hours significantly
Databricks Databricks-Certified-Data-Engineer-Associate Exam Domains Q&A
Certified instructors verify every question for 100% accuracy, providing detailed, step-by-step explanations for each.
Question 1
Databricks Databricks-Certified-Data-Engineer-Associate
QUESTION DESCRIPTION:
Which tool is used by Auto Loader to process data incrementally?
Correct Answer & Rationale:
Answer: A
Explanation:
Auto Loader in Databricks utilizes Spark Structured Streaming for processing data incrementally. This allows Auto Loader to efficiently ingest streaming or batch data at scale and to recognize new data as it arrives in cloud storage. Spark Structured Streaming provides the underlying engine that supports various incremental data loading capabilities like schema inference and file notification mode, which are crucial for the dynamic nature of data lakes.
[References:Databricks documentation on Auto Loader: Auto Loader Overview, , ]
Question 2
Databricks Databricks-Certified-Data-Engineer-Associate
QUESTION DESCRIPTION:
Which of the following commands will return the number of null values in the member_id column?
Correct Answer & Rationale:
Answer: C
Explanation:
To return the number of null values in the member_id column, the best option is to use the count_if function, which counts the number of rows that satisfy a given condition. In this case, the condition is that the member_id column is null. The other options are either incorrect or not supported by Spark SQL. Option A will return the number of non-null values in the member_id column. Option B will not work because there is no count_null function in Spark SQL. Option D will not work because there is no null function in Spark SQL. Option E will not work because there is no count_null function in Spark SQL. References:
Built-in Functions - Spark SQL, Built-in Functions
count_if - Spark SQL, Built-in Functions
Question 3
Databricks Databricks-Certified-Data-Engineer-Associate
QUESTION DESCRIPTION:
Which query is performing a streaming hop from raw data to a Bronze table?
A)

B)

C)

D)

Correct Answer & Rationale:
Answer: D
Explanation:
The query performing a streaming hop from raw data to a Bronze table is identified by using the Spark streaming read capability and then writing to a Bronze table. Let ' s analyze the options:
Option A: Utilizes .writeStream but performs a complete aggregation which is more characteristic of a roll-up into a summarized table rather than a hop into a Bronze table.
Option B: Also uses .writeStream but calculates an average, which again does not typically represent the raw to Bronze transformation, which usually involves minimal transformations.
Option C: This uses a basic .write with .mode( " append " ) which is not a streaming operation, and hence not suitable for real-time streaming data transformation to a Bronze table.
Option D: It employs spark.readStream.load() to ingest raw data as a stream and then writes it out with .writeStream, which is a typical pattern for streaming data into a Bronze table where raw data is captured in real-time and minimal transformation is applied. This approach aligns with the concept of a Bronze table in a modern data architecture, where raw data is ingested continuously and stored in a more accessible format.
[References:Databricks documentation on Structured Streaming: Structured Streaming in Databricks, , , , ]
Question 4
Databricks Databricks-Certified-Data-Engineer-Associate
QUESTION DESCRIPTION:
A Delta Live Table pipeline includes two datasets defined using STREAMING LIVE TABLE. Three datasets are defined against Delta Lake table sources using LIVE TABLE.
The table is configured to run in Development mode using the Continuous Pipeline Mode.
Assuming previously unprocessed data exists and all definitions are valid, what is the expected outcome after clicking Start to update the pipeline?
Correct Answer & Rationale:
Answer: B
Explanation:
The Continuous Pipeline Mode for Delta Live Tables allows the pipeline to run continuously and process data as it arrives. This mode is suitable for streaming ingest and CDC workloads that require low-latency updates. The Development mode for Delta Live Tables allows the pipeline to run on a dedicated cluster that is not shared with other pipelines. This mode is useful for testing and debugging the pipeline logic before deploying it to production. Therefore, the correct answer is B, because the pipeline will run continuously on a dedicated cluster until it is manually stopped, and the compute resources will be released only after the pipeline is shut down. References: Databricks Documentation - Configure pipeline settings for Delta Live Tables, Databricks Documentation - Continuous vs. triggered pipeline execution, Databricks Documentation - Development vs. production mode.
Question 5
Databricks Databricks-Certified-Data-Engineer-Associate
QUESTION DESCRIPTION:
A data engineer needs to use a Delta table as part of a data pipeline, but they do not know if they have the appropriate permissions.
In which of the following locations can the data engineer review their permissions on the table?
Correct Answer & Rationale:
Answer: E
Explanation:
Data Explorer is a graphical interface that allows you to browse, create, and manage data objects such as databases, tables, and views in your workspace. You can also review and modify the permissions on these data objects using Data Explorer. To access Data Explorer, you can click on the Data icon in the sidebar, or use the %sql magic command in a notebook. You can then select a database and a table, and click on the Permissions tab to view and edit the access control lists (ACLs) for the table. You can also use SQL commands such as SHOW GRANT and GRANT to query and modify the permissions on a Delta table. References:
Data Explorer
Access control for Delta tables
SHOW GRANT
[GRANT]
Question 6
Databricks Databricks-Certified-Data-Engineer-Associate
QUESTION DESCRIPTION:
A data engineer has created a new database using the following command:
CREATE DATABASE IF NOT EXISTS customer360;
In which of the following locations will the customer360 database be located?
Correct Answer & Rationale:
Answer: B
Explanation:
dbfs:/user/hive/warehouse Thereby showing " dbfs:/user/hive/warehouse/customer360.db
The location of the customer360 database depends on the value of the spark.sql.warehouse.dir configuration property, which specifies the default location for managed databases and tables. If the property is not set, the default value is dbfs:/user/hive/warehouse. Therefore, the customer360 database will be located in dbfs:/user/hive/warehouse/customer360.db. However, if the property is set to a different value, such as dbfs:/user/hive/database, then the customer360 database will be located in dbfs:/user/hive/database/customer360.db. Thus, more information is needed to determine the correct response.
Option A is not correct, as dbfs:/user/hive/database/customer360 is not the default location for managed databases and tables, unless the spark.sql.warehouse.dir property is explicitly set to dbfs:/user/hive/database.
Option B is not correct, as dbfs:/user/hive/warehouse is the default location for the root directory of managed databases and tables, not for a specific database. The database name should be appended with .db to the directory path, such as dbfs:/user/hive/warehouse/customer360.db.
Option C is not correct, as dbfs:/user/hive/customer360 is not a valid location for a managed database, as it does not follow the directory structure specified by the spark.sql.warehouse.dir property.
Databases and Tables
[Databricks Data Engineer Professional Exam Guide]
Question 7
Databricks Databricks-Certified-Data-Engineer-Associate
QUESTION DESCRIPTION:
An organization has data stored across multiple external systems, including MySQL, Amazon Redshift, and Google BigQuery. The data engineer wants to perform analytics without ingesting data directly into Databricks, while ensuring unified governance and minimizing data duplication.
Which feature of Databricks enables querying these external data sources while maintaining centralized governance?
Correct Answer & Rationale:
Answer: A
Explanation:
Lakehouse Federation is the Databricks feature built for querying external systems without moving all data into Databricks . Databricks documentation describes it as the platform for query federation , enabling users to run queries against multiple external data sources while keeping governance centralized through Unity Catalog . Databricks also documents support for external systems such as Amazon Redshift and other databases through connections and foreign catalogs, allowing read-only access to external data while managing permissions in Unity Catalog. This aligns directly with the requirement to minimize duplication and still maintain centralized governance. Databricks Connect is for local development against Databricks compute, not federated querying. MLflow is for machine learning lifecycle management. Delta Lake is a storage format and table layer, not a federation framework. Therefore, when the goal is unified governance across Databricks and external systems like MySQL, Redshift, and BigQuery without first ingesting the data, Lakehouse Federation is the documented answer. Databricks does note that for high-volume production ingestion, managed connectors may sometimes be preferred, but for direct querying without data movement, Lakehouse Federation is the correct feature.
Question 8
Databricks Databricks-Certified-Data-Engineer-Associate
QUESTION DESCRIPTION:
Which of the following describes the relationship between Bronze tables and raw data?
Correct Answer & Rationale:
Answer: E
Explanation:
Bronze tables are the first layer of a medallion architecture, which is a data design pattern used to organize data in a lakehouse. Bronze tables contain raw data ingested from various sources, such as RDBMS data, JSON files, IoT data, etc. The table structures in this layer correspond to the source system table structures “as-is”, along with any additional metadata columns that capture the load date/time, process ID, etc. The only transformation applied to the raw data in this layer is to apply a schema, which defines the column names and data types of the table. The schema can be inferred from the data source or specified explicitly. Applying a schema to the raw data enables the use of SQL and other structured query languages to access and analyze the data. Therefore, option E is the correct answer. References: What is a Medallion Architecture?, Raw Data Ingestion into Delta Lake Bronze tables using Azure Synapse Mapping Data Flow, Apache Spark + Delta Lake concepts, Delta Lake Architecture & Azure Databricks Workspace.
Question 9
Databricks Databricks-Certified-Data-Engineer-Associate
QUESTION DESCRIPTION:
A data engineer is standardizing repository layouts for multiple teams adopting Databricks Asset Bundles. The engineer wants to ensure every project has a single authoritative configuration file at the repository root that defines the bundle name, targets, workspace settings, permissions, and resource mappings (for jobs and pipelines).
Which strategy should the data engineer use to meet this goal?
Correct Answer & Rationale:
Answer: B
Explanation:
In Databricks Asset Bundles , the databricks.yml file located at the repository root serves as the single authoritative configuration file for the entire project. This file defines key elements such as the bundle name, deployment targets (for example, dev, test, prod), workspace configurations, permissions, and resource definitions including jobs and pipelines. Databricks documentation specifies that there must be one primary databricks.yml file at the root , ensuring consistency and simplifying deployment processes. However, to support modularity and maintainability, this root configuration file can reference additional YAML files using the include mapping. This allows teams to organize configurations across directories while still maintaining a single source of truth. Option A is incorrect because multiple root-level configuration files are not supported as independent authorities. Option C is invalid since configuration files are not restricted to hidden directories. Option D introduces ambiguity and contradicts the requirement for a single authoritative configuration. Therefore, using one root-level configuration file with optional includes is the correct and recommended approach.
Question 10
Databricks Databricks-Certified-Data-Engineer-Associate
QUESTION DESCRIPTION:
A data engineering team has noticed that their Databricks SQL queries are running too slowly when they are submitted to a non-running SQL endpoint. The data engineering team wants this issue to be resolved.
Which of the following approaches can the team use to reduce the time it takes to return results in this scenario?
Correct Answer & Rationale:
Answer: D
Explanation:
Option D is the correct answer because it enables the Serverless feature for the SQL endpoint, which allows the endpoint to automatically scale up and down based on the query load. This way, the endpoint can handle more concurrent queries and reduce the time it takes to return results. The Serverless feature also reduces the cold start time of the endpoint, which is the time it takes to start the cluster when a query is submitted to a non-running endpoint. The Serverless feature is available for both AWS and Azure Databricks platforms.
Databricks SQL Serverless, Serverless SQL endpoints, New Performance Improvements in Databricks SQL

Verified by Certified Instructors
This Databricks Databricks-Certified-Data-Engineer-Associate study pack was audited and verified on June 25, 2026 by Hilary Beaumont,. We ensure every technical rationale aligns with real-world enterprise standards.
A Stepping Stone for Enhanced Career Opportunities
Your profile having Databricks Certification certification significantly enhances your credibility and marketability in all corners of the world. The best part is that your formal recognition pays you in terms of tangible career advancement. It helps you perform your desired job roles accompanied by a substantial increase in your regular income. Beyond the resume, your expertise imparts you confidence to act as a dependable professional to solve real-world business challenges.
Your success in Databricks Databricks-Certified-Data-Engineer-Associate certification exam makes your visible and relevant in the fast-evolving tech landscape. It proves a lifelong investment in your career that give you not only a competitive advantage over your non-certified peers but also makes you eligible for a further relevant exams in your domain.
What You Need to Ace Databricks Exam Databricks-Certified-Data-Engineer-Associate
Achieving success in the Databricks-Certified-Data-Engineer-Associate Databricks exam requires a blending of clear understanding of all the exam topics, practical skills, and practice of the actual format. There's no room for cramming information, memorizing facts or dependence on a few significant exam topics. It means your readiness for exam needs you develop a comprehensive grasp on the syllabus that includes theoretical as well as practical command.
Here is a comprehensive strategy layout to secure peak performance in Databricks-Certified-Data-Engineer-Associate certification exam:
- Develop a rock-solid theoretical clarity of the exam topics
- Begin with easier and more familiar topics of the exam syllabus
- Make sure your command on the fundamental concepts
- Focus your attention to understand why that matters
- Ensure hands-on practice as the exam tests your ability to apply knowledge
- Develop a study routine managing time because it can be a major time-sink if you are slow
- Find out a comprehensive and streamlined study resource for your help
Ensuring Outstanding Results in Exam Databricks-Certified-Data-Engineer-Associate!
In the backdrop of the above prep strategy for Databricks-Certified-Data-Engineer-Associate Databricks exam, your primary need is to find out a comprehensive study resource. It could otherwise be a daunting task to achieve exam success. The most important factor that must be kep in mind is make sure your reliance on a one particular resource instead of depending on multiple sources. It should be an all-inclusive resource that ensures conceptual explanations, hands-on practical exercises, and realistic assessment tools.
Certachieve: A Reliable All-inclusive Study Resource
Certachieve offers multiple study tools to do thorough and rewarding Databricks-Certified-Data-Engineer-Associate exam prep. Here's an overview of Certachieve's toolkit:
Databricks Databricks-Certified-Data-Engineer-Associate PDF Study Guide
This premium guide contains a number of Databricks Databricks-Certified-Data-Engineer-Associate exam questions and answers that give you a full coverage of the exam syllabus in easy language. The information provided efficiently guides the candidate's focus to the most critical topics. The supportive explanations and examples build both the knowledge and the practical confidence of the exam candidates required to confidently pass the exam. The demo of Databricks Databricks-Certified-Data-Engineer-Associate study guide pdf free download is also available to examine the contents and quality of the study material.
Databricks Databricks-Certified-Data-Engineer-Associate Practice Exams
Practicing the exam Databricks-Certified-Data-Engineer-Associate questions is one of the essential requirements of your exam preparation. To help you with this important task, Certachieve introduces Databricks Databricks-Certified-Data-Engineer-Associate Testing Engine to simulate multiple real exam-like tests. They are of enormous value for developing your grasp and understanding your strengths and weaknesses in exam preparation and make up deficiencies in time.
These comprehensive materials are engineered to streamline your preparation process, providing a direct and efficient path to mastering the exam's requirements.
Databricks Databricks-Certified-Data-Engineer-Associate exam dumps
These realistic dumps include the most significant questions that may be the part of your upcoming exam. Learning Databricks-Certified-Data-Engineer-Associate exam dumps can increase not only your chances of success but can also award you an outstanding score.
Top Exams & Certification Providers
New & Trending
- New Released Exams
- Related Exam
- Hot Vendor
Verified Performance Reports
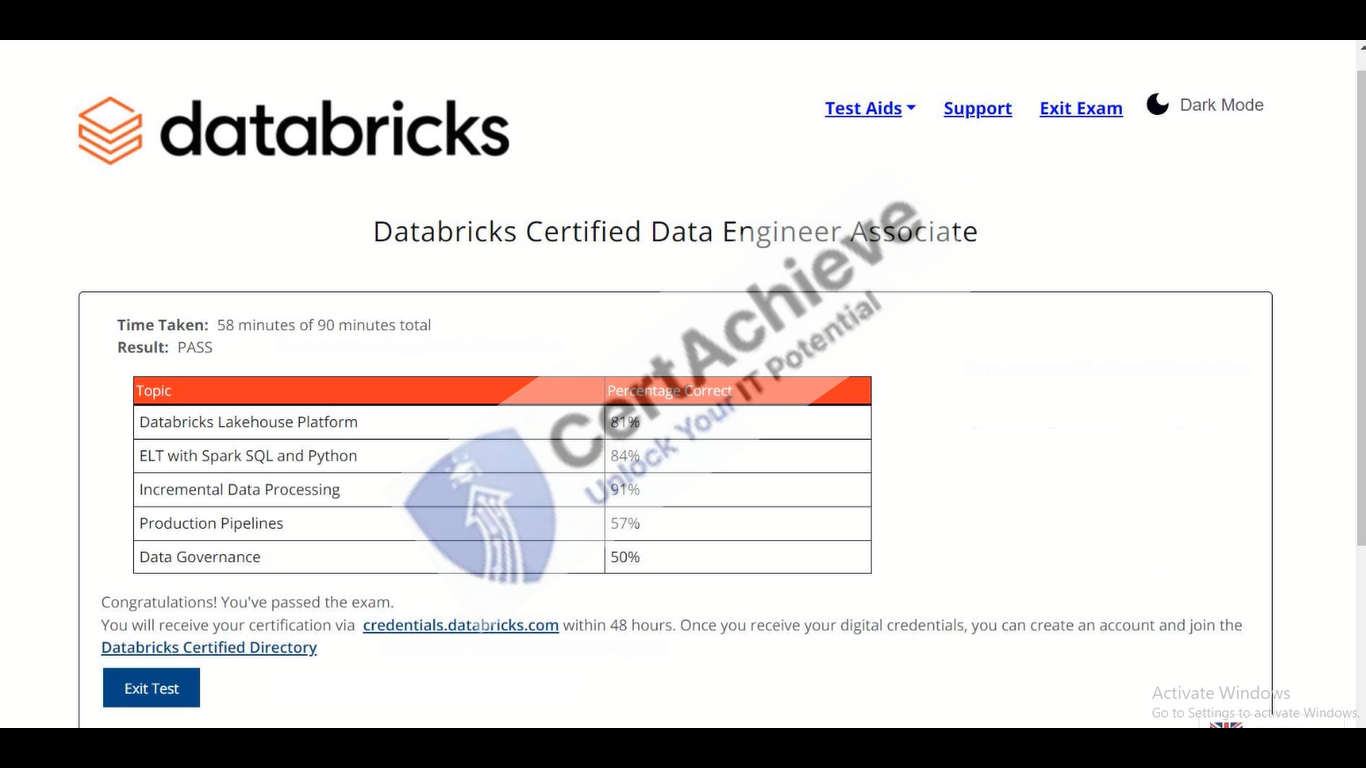
Authentic score reports from candidates who cleared the Databricks-Certified-Data-Engineer-Associate exam.
Verified Case #1
×
![]()